15 The Bootstrap
\[ \DeclareMathOperator{\E}{\mathbb{E}} \DeclareMathOperator{\R}{\mathbb{R}} \DeclareMathOperator{\RSS}{RSS} \DeclareMathOperator{\AIC}{AIC} \DeclareMathOperator{\bias}{bias} \DeclareMathOperator{\MSE}{MSE} \DeclareMathOperator{\VIF}{VIF} \DeclareMathOperator{\var}{Var} \DeclareMathOperator{\cov}{Cov} \DeclareMathOperator{\cor}{Cor} \DeclareMathOperator{\se}{se} \DeclareMathOperator{\trace}{trace} \DeclareMathOperator{\vspan}{span} \DeclareMathOperator{\proj}{proj} \newcommand{\condset}{\mathcal{Z}} \DeclareMathOperator{\cdo}{do} \newcommand{\ind}{\mathbb{I}} \newcommand{\T}{^\mathsf{T}} \newcommand{\X}{\mathbf{X}} \newcommand{\Y}{\mathbf{Y}} \newcommand{\Z}{\mathbf{Z}} \newcommand{\zerovec}{\mathbf{0}} \newcommand{\onevec}{\mathbf{1}} \newcommand{\trainset}{\mathcal{T}} \DeclareMathOperator*{\argmin}{arg\,min} \DeclareMathOperator*{\argmax}{arg\,max} \DeclareMathOperator{\SD}{SD} \newcommand{\dif}{\mathop{\mathrm{d}\!}} \newcommand{\convd}{\xrightarrow{\mathrm{D}}} \DeclareMathOperator{\logit}{logit} \newcommand{\ilogit}{\logit^{-1}} \DeclareMathOperator{\odds}{odds} \DeclareMathOperator{\dev}{Dev} \DeclareMathOperator{\sign}{sign} \DeclareMathOperator{\normal}{Normal} \DeclareMathOperator{\binomial}{Binomial} \DeclareMathOperator{\bernoulli}{Bernoulli} \DeclareMathOperator{\poisson}{Poisson} \DeclareMathOperator{\multinomial}{Multinomial} \DeclareMathOperator{\uniform}{Uniform} \DeclareMathOperator{\edf}{edf} \]
Note
This chapter is based partly on notes cowritten with Ann Lee and Mark Schervish for 36-402, themselves based in part by notes by Cosma Shalizi.
So far, when we have discussed inference (such as hypothesis tests and confidence intervals), we have used it to try to learn about the underlying population relationships, such as to do inference on the factors associated with some outcome. To do this inference, we relied on mathematical derivations of the distribution of estimators and statistics. These derivations rely on certain assumptions about the data and the population it is drawn from, and if those assumptions are not true, the derivations are not valid. This poses a problem if we want to model poorly behaved data. In this chapter, we’ll discuss a much more general procedure to estimate the distribution of estimators and statistics.
In very generic terms, we can think of the statistical inference process as:
- We obtain data \(X_1, X_2, \dots, X_n \sim F\), where \(F\) is an unknown population distribution.
- We calculate \(T = g(X_1, X_2, \dots, X_n)\), some statistic of interest. If we assume \(F\) is a distribution from some parametric family, \(T\) may be an estimator \(\hat \theta\) of the parameter \(\theta\) of that distribution. Because \(T\) is a function of the random sample, it is a random variable.
- To produce confidence intervals or tests, we want to know \(\var(T)\), which is the variance of \(T\) upon drawing repeated random samples of size \(n\) from \(F\). Or, depending on the situation, we may want to know the entire sampling distribution of \(T\).
We have previously achieved this in two ways:
- Direct calculation. In Theorem 5.4, for instance, we obtained \(\var(\hat \beta)\) for the OLS estimator by deriving its variance from a basic assumption about \(\var(e \mid X)\); in Definition 9.1, we derived an alternative estimator based on weaker assumptions.
- Large-sample approximation. For example, Theorem 11.2 describes the asymptotic distribution of the likelihood ratio test statistic as \(n \to \infty\); in finite samples, this is an approximation, but we can still use it to obtain approximate tests and confidence intervals.
But we often cannot use either approach. We might not believe the assumptions necessary for direct calculation, or our diagnostics may have given reason to doubt them; we might be using an estimator for which we do not know how to do the math; or the approximations necessary may turn out to be too approximate.
This is where the bootstrap comes in. The bootstrap is a general procedure to estimate the distribution of estimators and statistics. It still requires some conditions of the estimator and the data, but far fewer than our previous approaches, and is easy to implement without any complicated math.
15.1 The bootstrap procedure
Before we discuss the bootstrap for regression, let’s consider inference for a statistic \(T\), as above. We’ll then extend our results to regression.
The basic idea of the bootstrap comes from putting two simple ideas together. First: If it were possible to obtain \(B\) repeated samples \(X_1, X_2, \dots, X_n \sim F\), calculating \(T_1, T_2, \dots, T_B\), we could estimate \(\var(T)\) by calculating the sample variance of \(T_1, T_2, \dots, T_B\). We could similarly estimate any other property of the distribution of \(T\) by obtaining enough samples and estimating it.
Of course, the problem is we can’t obtain \(B\) repeated samples from \(F\). That’s why the second idea is also necessary. We do not know \(F\), but we have \(n\) samples from it. If \(F(x)\) is the cumulative distribution function (cdf), we can approximate the cdf by its empirical version, and we can draw new samples from this approximation of the population distribution \(F\).
Definition 15.1 (Empirical cdf) If \(X_1, X_2, \dots, X_n \sim F\), where \(F\) is an unknown distribution with cdf \(F(x)\), then the empirical cdf is \[ \hat F(x) = \frac{1}{n} \sum_{i=1}^n \ind(X_i \leq x), \] where \(\ind(\cdot)\) is the indicator function that is 1 if its argument is true and 0 otherwise.
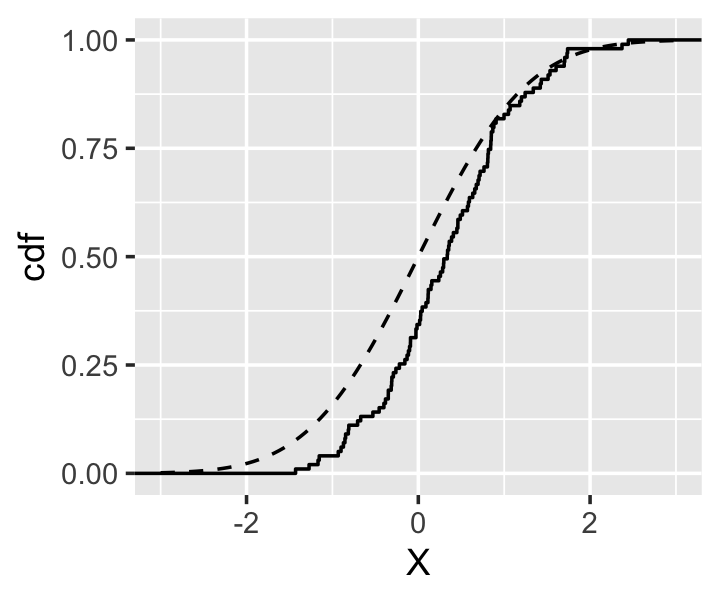
Example 15.1 Suppose \(F\) is the standard normal distribution and \(n = 100\). Figure 15.1 shows the empirical cdf calculated from such a sample, compared to the true standard normal cdf. The empirical cdf matches quite closely.
To draw samples from \(\hat F\), it is sufficient to draw samples with replacement from \(X_1, X_2, \dots, X_n\). This leads to the bootstrap procedure.
Definition 15.2 (The bootstrap) Given a sample \(X_1, X_2, \dots, X_n\) from an unknown distribution \(F\), and a statistic \(T = g(X_1, X_2, \dots, X_n)\), the bootstrap estimate of \(\var(T)\) is obtained by the following steps:
- Estimate \(\hat F\) using the empirical cdf.
- Draw \(X_1^*, X_2^*, \dots, X_n^* \sim \hat F\).
- Compute \(T^* = g(X_1^*, X_2^*, \dots, X_n^*)\).
- Repeat steps 2 and 3 \(B\) times, to get \(T_1^*, T_2^*, \dots, T_B^*\).
- Let \[ \widehat{\var}(T) = \frac{1}{B} \sum_{b=1}^B \left(T_b^* - \frac{1}{B} \sum_{r = 1}^B T_r^*\right)^2, \] the sample variance of \(T_1^*, \dots, T_B^*\).
We can think of this procedure as making two approximations:
- We use \(\hat F \approx F\) to approximate drawing from the population distribution. This approximation’s quality depends on \(n\).
- We approximate the variance of \(T\) using only \(B\) bootstrap samples. We can make this error small by making \(B\) large, unless it is too computationally intensive to do so.
For more details on the error inherent in the bootstrap, see Davison and Hinkley (1997), section 2.5.2. For a discussion of the technical conditions under which bootstrap methods work and don’t work, see Davison and Hinkley (1997), section 2.6.
15.2 Bootstrap confidence intervals
A common application of the bootstrap is the construction of confidence intervals. A \(1 - \alpha\) confidence interval for a parameter \(\theta\) is defined as an interval \([L, U]\) such that \[ \Pr(L \leq \theta \leq U) = 1 - \alpha. \] Here \(L\) and \(U\) are random, because they are calculated from the random data; \(\theta\) is a fixed population parameter. The probability, then, is over repeated resampling of the population, and says that a procedure for generating 95% confidence intervals should produce intervals that cover the population parameter 95% of the time.
We can use the bootstrap to obtain confidence intervals.
Theorem 15.1 (Pivotal bootstrap confidence intervals) If \(X_1, X_2, \dots, X_n \sim F\), and we are interested in estimating a population parameter \(\theta\), we can use the bootstrap to obtain \(\hat \theta_1^*, \hat \theta_2^*, \dots, \hat \theta_B^*\). Then a \(1 - \alpha\) bootstrap confidence interval for \(\theta\) is the interval \[ [2 \hat \theta - q_{1 - \alpha/2}, 2\hat \theta - q_{\alpha/2}], \] where \(\hat \theta\) is the estimate calculated from the sample \(X_1, X_2, \dots, X_n\), and \(q_\alpha\) is the \(\alpha\) quantile of the bootstrap estimates \(\hat \theta_b^*\).
This interval is first-order accurate, meaning \(\Pr(L \leq \theta \leq U) = 1 - \alpha + O(n^{-1/2})\).
Proof. By definition of the quantiles, we have: \[\begin{align*} 1 - \alpha &= \Pr\left(q_{\alpha/2} \leq \hat \theta^* \leq q_{1 - \alpha/2}\right)\\ &= \Pr\left(q_{\alpha/2} - \hat{\theta} \leq \hat \theta^* - \hat{\theta} \leq q_{1-\alpha/2} - \hat{\theta} \right). \end{align*}\] Here \(\hat \theta\) is fixed (to the value obtained from our sample) and \(\hat \theta^*\) is a random variable, since it is obtained from random bootstrap samples. If the distribution of \(\hat \theta - \theta\) (where \(\theta\) is fixed and \(\hat \theta\) is random) is approximately equal to the distribution of \(\hat \theta^* - \hat \theta\), then \[\begin{align*} 1 - \alpha &\approx \Pr\left(q_{\alpha/2} - \hat \theta \leq \hat \theta - \theta \leq q_{1 - \alpha/2} - \hat \theta\right)\\ &= \Pr\left(q_{\alpha/2} - 2 \hat \theta \leq - \theta \leq q_{1 - \alpha/2} - 2 \hat \theta\right)\\ &= \Pr\left(2 \hat \theta - q_{1 - \alpha/2} \leq \theta \leq 2 \hat \theta - q_{\alpha/2}\right). \end{align*}\]
It is reasonable to argue the distributions are similar: \(\theta\) is the population value and \(\hat \theta\) is the estimate from a sample, so the distribution of \(\hat \theta - \theta\) reflects the bias and variance of the estimator. In the bootstrap processing, \(\hat \theta\) is the “population” parameter (for our “population” \(\hat F\)) and \(\hat \theta^*\) is the estimate for samples drawn from that “population”. Provided the bias and variance of the estimator do not vary with the value of the parameter, these quantities are pivotal and the approximation is valid.
To establish the accuracy of the interval, see Davison and Hinkley (1997), section 5.4.1.
You might be wondering why we can’t use a much simpler confidence interval: Why shouldn’t we use \([q_{\alpha/2}, q_{1-\alpha/2}]\)? If \(\hat F \approx F\), surely these should approximate the quantiles of the sampling distribution of \(\hat \theta\). Indeed, this is also a first-order accurate confidence interval, but its behavior in finite samples can be poor. For example, if the estimator is biased, the quantiles of \(\hat \theta^*\) will be shifted relative to \(\theta\), so the coverage of \([q_{\alpha/2}, q_{1-\alpha/2}]\) may be terrible. The pivotal interval, on the other hand, works as long as the bias in the sample (the distribution of \(\hat \theta - \theta\)) is the same as the bias in the bootstrap samples (the distribution of \(\hat \theta^* - \hat \theta\)). This is strictly weaker. Provided the estimator is at least consistent, this difference should disappear as \(n \to \infty\), but it can be a serious issue in finite samples.
There are in fact many variations of procedures for producing bootstrap confidence intervals, each with different asymptotic properties. Some of these have coverage probability \(1 - \alpha + O(n^{-1})\), which is better than the pivotal intervals described above. For detailed discussion, see Davison and Hinkley (1997), chapter 5.
More recently, specialized (and more computationally intensive) bootstrap confidence interval methods for linear regression have been developed. One recent method, which achieves coverage probability \(1 - \alpha + O(n^{-2})\), is given by McCarthy et al. (2018).
15.3 Resampling cases in regression
Now that we know a general procedure for inference and confidence intervals, let’s apply it to regression. To do so, we must decide what is random and what is fixed. Conventionally, as in Chapter 5, we treat \(X\) as fixed and \(Y\) as random. If our regression model is \(Y = r(X) + e\), for some function \(r\) (such as a linear function), we might trust our estimate \(\hat r(X)\), fix \(X\), and draw new errors to obtain \(Y^*\). We could do this, for instance, by estimating the distribution of \(e\) using the observed distribution of the residuals \(\hat e\).
But if we are making few assumptions about the data and its distributions, it may be more reasonable to assume \(X\) and \(Y\) are both random. We obtain samples \(X, Y \sim F\), where \(F\) is an unknown population distribution; to bootstrap, we need a way to simulate new data \((X_1^*, Y_1^*), \dots, (X_n^*, Y_n^*)\) from an approximation of \(F\). We can do this using the x-y bootstrap, also known as resampling cases, or just “the” bootstrap.
This bootstrap works in exactly the same way as the bootstrap in the univariate case. It may seem less obvious how to define an empirical cdf \(F(x, y)\) for data where \(X \in \R^p\), but it is still true that drawing \((X, Y)\) pairs with replacement from the sample is the same as drawing from the empirical distribution \(\hat F\).
Definition 15.3 (The x-y bootstrap) Given a sample \((X_1, Y_1), (X_2, Y_2), \dots, (X_n, Y_n)\) from an unknown distribution \(F\), and a statistic \(T\) calculated from this sample, the x-y bootstrap estimate of \(\var(T)\) is obtained by the following steps:
- Draw \((X_1^*, Y_1^*), (X_2^*, Y_2^*), \dots, (X_n^*, Y_n^*)\) by sampling \(n\) observations with replacement from the data.
- Compute \(T\), the statistic of interest.
- Repeat steps 1 and 2 \(B\) times, to get \(T_1^*, T_2^*, \dots, T_B^*\).
- Let \[ \widehat{\var}(T) = \frac{1}{B} \sum_{b=1}^B \left(T_b^* - \frac{1}{B} \sum_{r = 1}^B T_r^*\right)^2, \] the sample variance of \(T_1^*, \dots, T_B^*\).
Here \(T\) could be a coefficient from a particular model fit to the data; for instance, \(T\) could be \(\hat \beta_1\), and estimating its variance could help us calculate a standard error; or we could use the bootstrap samples to calculate a pivotal confidence interval following the procedure of Theorem 15.1.
Example 15.2 (Bootstrapping with rsample) The rsample package is meant to make it easy to do bootstrap sampling, as well as to do cross-validation (which we will see later). We will use it for all our bootstrapping.1
Let’s consider the cats data from Exercise 7.1. Let’s again consider predicting heart weight from body weight:
library(MASS)
library(dplyr)
library(rsample)
cat_fit <- lm(Hwt ~ Bwt, data = cats)Let’s try to obtain a 95% confidence interval for the Bwt coefficient. To do so, we can obtain \(B = 1000\) bootstrap samples from the original data frame, each by drawing \(n = 144\) observations with replacement from the cats data frame (which has 144 rows). The bootstraps() function automatically does resampling with replacement from a dataframe:
boot_samps <- bootstraps(cats, times = 1000)
head(boot_samps)# A tibble: 6 × 2
splits id
<list> <chr>
1 <split [144/58]> Bootstrap0001
2 <split [144/54]> Bootstrap0002
3 <split [144/49]> Bootstrap0003
4 <split [144/58]> Bootstrap0004
5 <split [144/55]> Bootstrap0005
6 <split [144/57]> Bootstrap0006boot_samps is now a data frame containing 1000 rows, each of which has a label (id) and an object containing the resampled data. (This is called splits because the package also does cross-validation, where we split the data into training and test sets.)
To finish the bootstrap procedure, we need to refit the model to each of the 1000 bootstrap samples and obtain the Bwt coefficient from each fit. We can use sapply to call a function with each bootstrap sample. Within that function, we call analysis() to get the analysis set (the data to fit the model to) from the object bootstraps() created, and then we can fit a model and get the coefficient.
bwts <- sapply(boot_samps$splits, function(sample) {
boot_data <- analysis(sample)
boot_fit <- lm(Hwt ~ Bwt, data = boot_data)
return(coef(boot_fit)["Bwt"])
})bwts is now a vector of 1000 coefficients from our 1000 bootstrap samples. Its sample standard deviation is
sd(bwts)[1] 0.3032436This is a bootstrap estimate of the standard error. This is larger than the estimate using Theorem 5.4, which is \(0.25\).
We can then apply Theorem 15.1 to obtain a 95% confidence interval for the Bwt coefficient:
2 * coef(cat_fit)["Bwt"] - quantile(bwts, c(0.975, 0.025),
names = FALSE)[1] 3.440529 4.617619Compare that to the value calculated by R based on the \(t\) distribution procedure in Section 5.4.1:
confint(cat_fit)["Bwt", ] 2.5 % 97.5 %
3.539343 4.528782 The bootstrap interval is slightly wider. That is not too surprising, as it assumes a random \(X\), rather than keeping \(X\) fixed as the \(t\)-based interval does.
You can think of a template for bootstrapping regression. If you want to bootstrap \(T\), some statistic calculated from the model, then:
- Use rsample’s
bootstraps()to obtain the bootstrap samples \(b = 1, \dots, B\). Typically \(B = 1000\) or larger. - Write a function that fits your desired model to a sample \(b\) and extracts \(T_b^*\).
- Apply that function to each bootstrap sample. You can use
sapply, or if you’re already familiar with the purrr package, you can use any of its map family of functions. - Using \(T_1^*, T_2^*, \dots, T_B^*\), calculate your bootstrap standard error, confidence interval, or any other desired quantity.
The same procedure can be applied to ordinary linear models, to any generalized linear model, or to any model based on an iid sample from a population \(F\). (If the sample is not iid, then resampling from the observed data is not like obtaining a sample from the population.)
Exercises
Exercise 15.1 (Width of bootstrap confidence intervals) In Exercise 9.4, you simulated data for linear regression with heteroskedastic errors. Specifically, the standard deviation of the errors was proportional to \(X_2 / 10\).
Consider estimating \(\E[Y \mid X_1 = 5, X_2 = 1]\) using linear regression. Produce a confidence interval using
predict()and itsintervalargument, then produce a pivotal bootstrap confidence interval (Theorem 15.1).Now consider estimating \(\E[Y \mid X_1 = 5, X_2 = 9]\). Again produce a confidence interval using standard errors from
predict()and a separate pivotal bootstrap confidence interval.You should see that in one case, the standard interval is wider, but in the other case the bootstrap interval is wider. Explain why.
Hint: The difference between these two predictions is \(X_2\). This means \(\var(Y \mid X_1 = x_1, X_2 = x_2)\) is different as well.
Exercise 15.2 (Inheritance of height redux) In Exercise 7.2, you related the heights of mothers and their adult daughters to study the inheritance of height. Repeat your regression from that problem and find a pivotal bootstrap confidence interval for the mheight coefficient.
Exercise 15.3 (Insect attraction to light, redux) In Exercise 13.6, you used a generalized linear model to model the number of insects collected in light traps as a function of light type, location, temperature, humidity, and moon phase. In part 4, you gave a 95% confidence interval for the coefficient for temperature.
- Produce a 95% pivotal bootstrap confidence interval for the same coefficient.
- Comment on the difference between this confidence interval and the original one. Your original CI was based on an asymptotic result (either the Wald intervals, based on asymptotic normality, or profile likelihood intervals, based on the asymptotic distribution of the likelihood ratio statistic), so it was not exact. (See Section 12.6.2.)
Exercise 15.4 (Bootstrapping the GMP data) TODO HW8 #2 (d)
Exercise 15.5 (Bootstrapping a biased estimator) We obtain a sample \(X_1, \dots, X_n \sim F\) and estimate a population parameter \(\theta\) using an unbiased estimator \(\hat \theta\). We also create a biased estimator \(\hat \theta_b = \hat \theta + b\), where \(b\) is a nonzero constant.
Consider using the bootstrap to produce a confidence interval for \(\theta\). The basic premise of the bootstrap is that drawing bootstrap samples from the observed data is analogous to drawing the observed data from the population. Given the observed sample, then, we expect the bootstrap estimates \(\hat \theta_b\) to be similarly biased: conditional on a particular bootstrap sample with estimate \(\hat \theta_b\), we expect the bootstrapped estimates \(\hat \theta_b^*\) to have the bias \[ \E[\hat \theta_b^* - \hat \theta_b \mid \hat \theta_b] = b. \]
Let \(q_\alpha(\hat \theta)\) denote the \(\alpha\) quantile of the sampling distribution of \(\hat \theta\), and similarly let \(q_\alpha(\hat \theta_b)\) and \(q_\alpha(\hat \theta_b^*)\) denote the quantiles of the respective sampling distributions.
Given the definition of \(\hat \theta_b\), relate \(q_\alpha(\hat \theta_b)\) and \(q_\alpha(\hat \theta_b^*)\) to the quantile of the sampling distribution for the unbiased estimator.
Based on this, compare the simple percentile-based confidence interval using \(\hat \theta_b\), which is \([q_{\alpha/2}(\hat \theta_b^*), q_{1 - \alpha/2}(\hat \theta_b^*)]\), to the “ideal” interval \([q_{\alpha/2}(\hat \theta), q_{1 - \alpha/2}(\hat \theta)]\). How is it shifted relative to the ideal interval?
Now compare the pivotal bootstrap confidence interval (Theorem 15.1) using the biased \(\hat \theta_b\). Show that for this interval, the bias is canceled out.
This illustrates why the pivotal interval is superior, though it is still only first-order accurate and can perform poorly in small samples.
The boot package is designed specifically for bootstrapping and supports doing bootstrap calculations in parallel, but it is much more complicated than we need here—it supports many varieties of bootstrap sampling we will not be using.↩︎