library(regressinator)
nice_pop <- population(
x1 = predictor(rnorm, mean = 5, sd = 4),
x2 = predictor(runif, min = 0, max = 10),
y = response(
4 + 2 * x1 - 3 * x2, # relationship between X and Y
error_scale = 3.0 # errors are multiplied by this scale factor
)
)8 The Regressinator
\[ \DeclareMathOperator{\E}{\mathbb{E}} \DeclareMathOperator{\R}{\mathbb{R}} \DeclareMathOperator{\RSS}{RSS} \DeclareMathOperator{\AIC}{AIC} \DeclareMathOperator{\bias}{bias} \DeclareMathOperator{\MSE}{MSE} \DeclareMathOperator{\VIF}{VIF} \DeclareMathOperator{\var}{Var} \DeclareMathOperator{\cov}{Cov} \DeclareMathOperator{\cor}{Cor} \DeclareMathOperator{\se}{se} \DeclareMathOperator{\trace}{trace} \DeclareMathOperator{\vspan}{span} \DeclareMathOperator{\proj}{proj} \newcommand{\condset}{\mathcal{Z}} \DeclareMathOperator{\cdo}{do} \newcommand{\ind}{\mathbb{I}} \newcommand{\T}{^\mathsf{T}} \newcommand{\X}{\mathbf{X}} \newcommand{\Y}{\mathbf{Y}} \newcommand{\Z}{\mathbf{Z}} \newcommand{\zerovec}{\mathbf{0}} \newcommand{\onevec}{\mathbf{1}} \newcommand{\trainset}{\mathcal{T}} \DeclareMathOperator*{\argmin}{arg\,min} \DeclareMathOperator*{\argmax}{arg\,max} \DeclareMathOperator{\SD}{SD} \newcommand{\dif}{\mathop{\mathrm{d}\!}} \newcommand{\convd}{\xrightarrow{\mathrm{D}}} \DeclareMathOperator{\logit}{logit} \newcommand{\ilogit}{\logit^{-1}} \DeclareMathOperator{\odds}{odds} \DeclareMathOperator{\dev}{Dev} \DeclareMathOperator{\sign}{sign} \DeclareMathOperator{\normal}{Normal} \DeclareMathOperator{\binomial}{Binomial} \DeclareMathOperator{\bernoulli}{Bernoulli} \DeclareMathOperator{\poisson}{Poisson} \DeclareMathOperator{\multinomial}{Multinomial} \DeclareMathOperator{\uniform}{Uniform} \DeclareMathOperator{\edf}{edf} \]
The regressinator is an R package that can simulate data from different regression models with different error distributions and population relationships. It can also present different regression diagnostics in “lineup plots”, which help us see how diagnostics can look for well-specified and incorrectly specified models. We will use it throughout the rest of the book for simulations and activities.
For more information about the regressinator, including an introductory guide and a reference manual, see its website and the accompanying paper (Reinhart 2026).
8.1 Simulating a population
To demonstrate how the regressinator works, let’s specify a simple situation where all model assumptions hold. We define a “population”, which specifies the population distribution of \(X\), the relationship between \(X\) and \(Y\), and the distribution of \(e\).
The predictor() function lets us specify the distribution each predictor is drawn from, by naming a function that can be used to draw from it and arguments to provide to that function. The response() function’s first argument is an expression, in terms of the predictors, for the mean of the response, to which errors will be added. (We will define this slightly differently when we get to generalized linear models in Chapter 13.) By default, the errors are drawn from a standard normal distribution, which we can rescale to have different standard deviation using the error_scale argument.
We can use the sample_x() and sample_y() functions to obtain a sample from this population:
nice_sample <- nice_pop |>
sample_x(n = 100) |>
sample_y()
head(nice_sample)Sample of 6 observations from
Population with variables:
x1: rnorm(list(mean = 5, sd = 4))
x2: runif(list(min = 0, max = 10))
y: gaussian(4 + 2 * x1 - 3 * x2, error_scale = 3)
# A tibble: 6 × 3
x1 x2 y
<dbl> <dbl> <dbl>
1 1.34 0.792 10.00
2 7.18 5.99 3.71
3 8.02 8.39 -6.33
4 0.774 7.47 -11.9
5 0.473 6.44 -17.2
6 6.71 4.52 4.26This is an ordinary data frame (just with a couple extra attributes to store population information), and we can easily plot it:
library(ggplot2)
ggplot(nice_sample, aes(x = x1, y = y)) +
geom_point()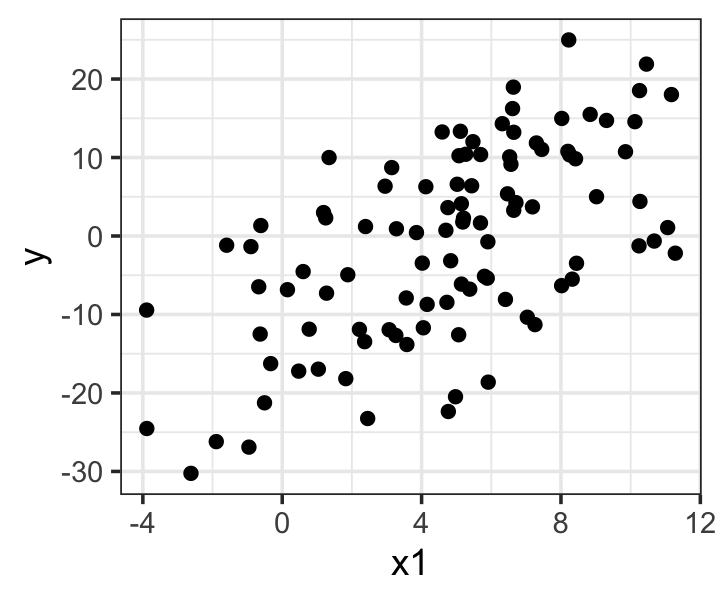
As a demonstration, let’s simulate the sampling distribution of \(\hat \beta\). Remember regression inference is usually in the fixed-\(X\) setting, so we will use the \(X\) values from nice_sample repeatedly; sample_y() will just overwrite the y column. The regressinator provides the sampling_distribution() function to do this automatically. By default, it will repeatedly call sample_y() on the data provided to it, refit the model to that data, and call broom::tidy() to get a data frame of the model coefficients. These data frames are then combined into one large data frame with a .sample column indicating which fit each coefficient came from.
B <- 1000
fit <- lm(y ~ x1 + x2, data = nice_sample)
cis <- confint(fit)
coefs <- sampling_distribution(fit, nice_sample, nsim = B)coefs, showing estimated coefficients from the original fit and the first two simulations.
| term | estimate | std.error | statistic | p.value | .sample |
|---|---|---|---|---|---|
| (Intercept) | 3.342 | 0.646 | 5.173 | 0.000 | 0 |
| x1 | 2.231 | 0.072 | 31.138 | 0.000 | 0 |
| x2 | -2.919 | 0.094 | -30.892 | 0.000 | 0 |
| (Intercept) | 2.084 | 0.665 | 3.134 | 0.002 | 1 |
| x1 | 2.102 | 0.074 | 28.493 | 0.000 | 1 |
| x2 | -2.774 | 0.097 | -28.521 | 0.000 | 1 |
| (Intercept) | 3.823 | 0.729 | 5.246 | 0.000 | 2 |
| x1 | 1.953 | 0.081 | 24.165 | 0.000 | 2 |
| x2 | -2.860 | 0.107 | -26.838 | 0.000 | 2 |
As we can see in Table 8.1, coefs contains the \(\hat \beta\) values from each simulation. There are various ways to extract estimates for specific predictors. For example, using dplyr, we could group by the term column and use summarize() to get means or other summary statistics within each group:
library(dplyr)
coefs |>
group_by(term) |>
summarize(mean_se = mean(std.error))# A tibble: 3 × 2
term mean_se
<chr> <dbl>
1 (Intercept) 0.708
2 x1 0.0785
3 x2 0.103 See Wickham et al. (2023) chapter 3 if you are unfamiliar with dplyr and need an introduction. We could alternately use R’s indexing to select a column corresponding to a particular term:
coefs[coefs$term == "x1", "std.error"] |>
head()# A tibble: 6 × 1
std.error
<dbl>
1 0.0717
2 0.0738
3 0.0808
4 0.0797
5 0.0785
6 0.0818Data frames are indexed by their rows and columns, so we select the rows by passing a logical vector (coefs$term == "x1") that is TRUE for the rows we want, and we select the column by giving its name.
8.2 Lineups for diagnostics
To help us learn to interpret regression diagnostic plots, the regressinator can produce “lineups”. The lineup process, introduced by Buja et al. (2009), is a way to conduct statistically sound hypothesis tests visually with well-chosen plots, rather than mathematically with well-chosen test statistics. The core idea is simple: If we are looking for a particular pattern in a plot as a sign our null hypothesis is false, then hide the plot among 19 other plots simulated so the null hypothesis is true. If we can distinguish the plot with real data from those where the null hypothesis is true, that is like a test statistic being far from the null distribution; if a test statistic is larger than 19 draws from its null distribution, then \(p < 0.05\).
In regression, we can think of the null hypothesis as being that the model is correctly specified. We examine diagnostic plots to determine whether to reject the null (and perhaps make revisions to our model), but it can be difficult to tell if a particular diagnostic plot reveals a real problem or if a pattern we observe is just random noise. Lineups can help us here too (Loy 2021).
The regressinator provides the model_lineup() function. It takes a model fit and does the following:
- Get the diagnostics from that model (using
augment(), by default) - Simulate 19 additional datasets using the model, using the standard assumptions for that model. (For instance, for linear regression, errors are drawn from a normal distribution.) In each dataset, the same \(\X\) values are used, and only new \(\Y\) values are drawn. Each dataset is the same size.
- For each of those datasets, fit the same model and calculate the diagnostics.
- Put the diagnostics for all 20 fits into one data frame with a
.samplecolumn indicating which fit each diagnostic came from. - Print out a message indicating how to tell which of the
.samplevalues comes from the original model.
This helps us compare how diagnostic plots will look when assumptions hold (by looking at the 19 simulated datasets) to how the diagnostic plots of our real model look. We can construct a plot using the returned data frame, faceting by the .sample column so we get one plot per simulated (or real) dataset. (If you’re not familiar with ggplot2 and faceting, see chapter 9 of Wickham et al. (2023).)
We’ll consider many examples of the use of lineup plots to detect model problems in Chapter 9.
Exercises
Exercise 8.1 (Bias and variance) In Section 8.1, the rows of coefs are, in effect, samples from the population sampling distribution of \(\hat \beta\).
Run the code in Section 8.1 to define the population and model, then analyze coefs to answer the following questions.
- Are the estimates biased?
- Does the estimate of \(\var(\hat \beta)\) provided by
vcov(fit)appear reasonably accurate? (You need only check the entries on the diagonal, i.e. the estimated variance of each coefficient, not the covariances.)
Hint: Grouping by the “term” column gives each term in its own group, so you can then use dplyr’s summarize() to get means, standard deviations, and so on.
Exercise 8.2 (Confidence interval coverage) Continuing from the previous exercise, we can get confidence intervals from each model fit as well:
# sampling_distribution uses broom::tidy() to get the
# coefficients, and we can give it `conf.int = TRUE`
# to get CIs
coefs_cis <- sampling_distribution(fit, nice_sample, nsim = B,
conf.int = TRUE)A 95% confidence interval has correct coverage if 95% of confidence intervals cover (include) the true parameter value. Check if these confidence intervals have approximate 95% coverage.
Exercise 8.3 (Diagnosing a nonlinear trend) Consider a simple dataset where the true relationship is not linear, but we fit a linear model:
nonlinear_pop <- population(
x1 = predictor(runif, min = 1, max = 8),
y = response(0.7 + x1**2, family = gaussian(),
error_scale = 4.0)
)
nonlinear_data <- sample_x(nonlinear_pop, n = 100) |>
sample_y()
nonlinear_fit <- lm(y ~ x1, data = nonlinear_data)Since model_lineup() uses augment() on each fit by default, we get fitted values and residuals for each fit. We can plot these and facet by .sample:
model_lineup(nonlinear_fit) |>
ggplot(aes(x = .fitted, y = .resid)) +
geom_point() +
facet_wrap(vars(.sample)) +
labs(x = "Fitted value", y = "Residual")decrypt("vAgi SKMK 7l 5y07M7yl 4b")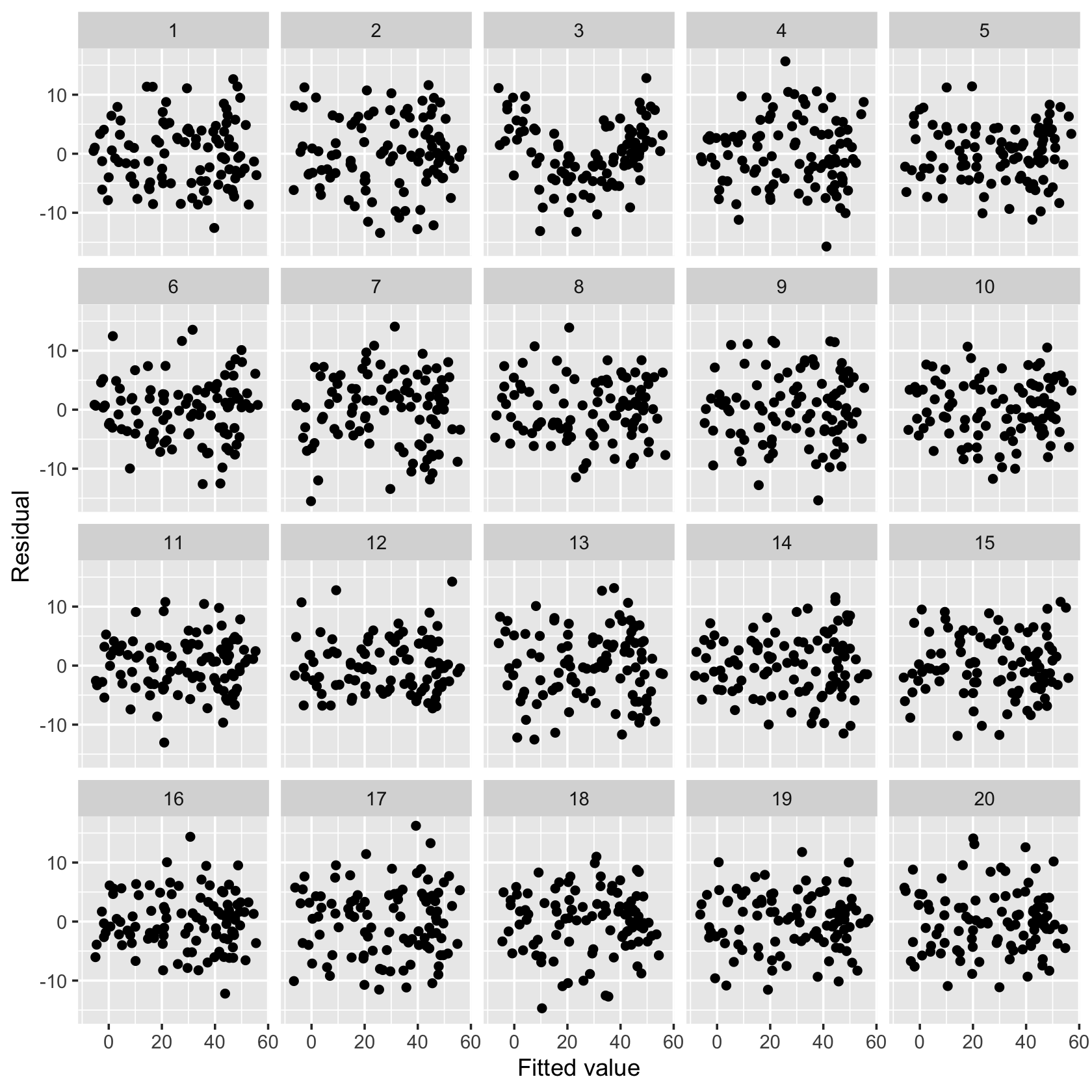
Examine the 20 plots and guess which one represents the model fit to the original data. Paste the decrypt() message into your R console to see if you were right.
Exercise 8.4 (Hurdling) Example 7.1 suggests a situation in which
- hurdling ability is positively associated with height, when controlling for weight,
- height and weight are positively correlated, but
- marginally, height is negatively correlated with hurdling ability.
Use the regressinator to define such a population. Sample \(n = 100\) observations and fit two linear models (one with height and one with both height and weight) to demonstrate the slopes have opposite signs.
Hint: The mvtnorm package provides an rmvnorm function to generate from the multivariate normal distribution. You can use this in predictor() to generate bivariate normal height and weight variables. Access the help with help(predictor) to see examples.